

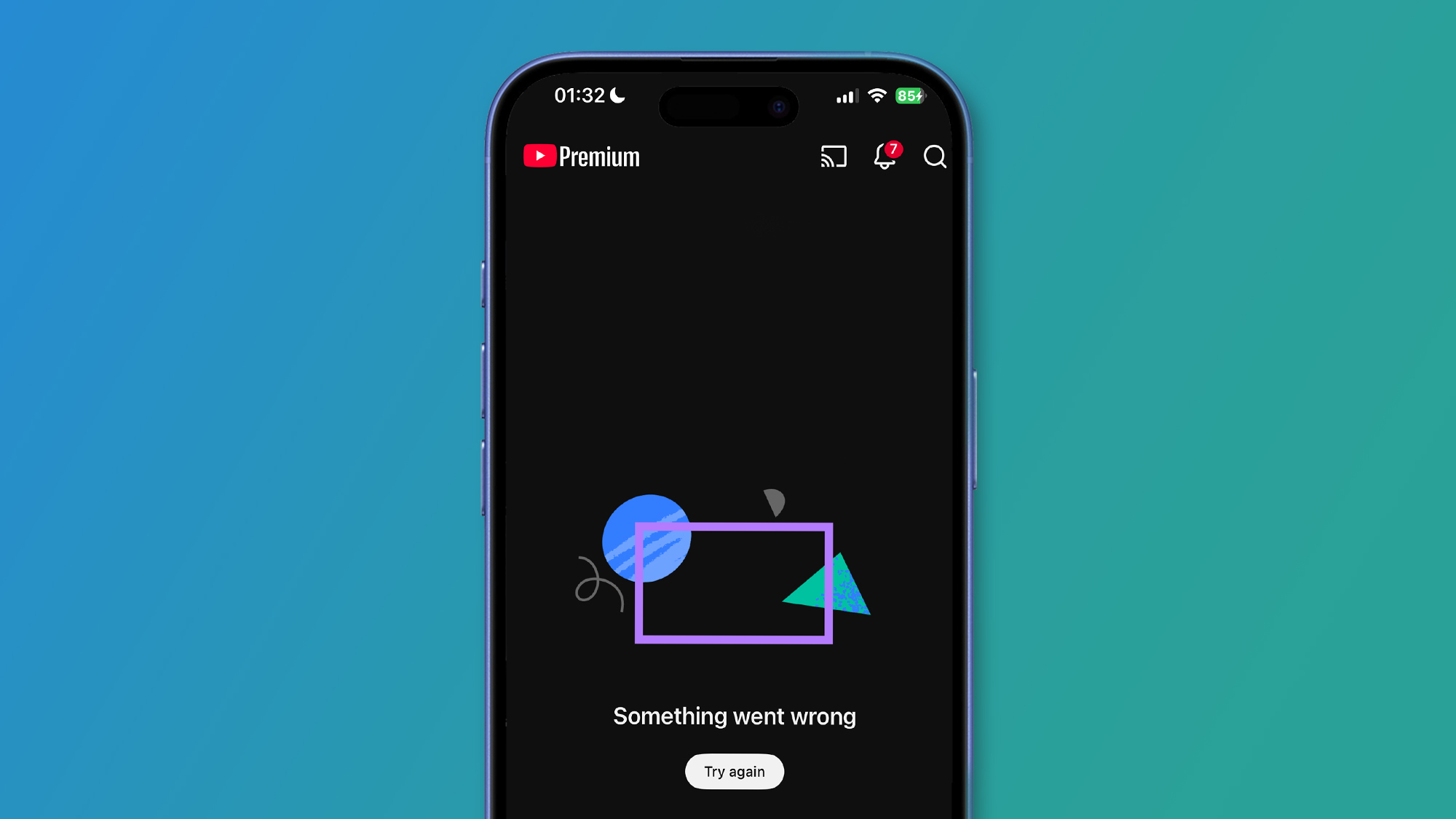
On the evening of February 17, 2026, millions of YouTube users around the world encountered an unexpected message: "Something went wrong." For several hours, the world's largest video platform experienced a major global outage that left over 320,000 users in the United States alone unable to access their homepage, recommendations, or in some cases, even play videos. This incident wasn't just another technical glitch—it was a rare system-wide failure that revealed just how dependent we've become on complex digital infrastructure and how a single point of failure can disrupt a service used by billions.
How YouTube's Massive Infrastructure Actually Works
To understand why YouTube goes down, we first need to understand how it works. YouTube isn't just a simple website—it's one of the most complex distributed systems ever built. The platform runs on Google's global cloud infrastructure, which spans hundreds of data centers across the world. When you upload a video, it doesn't just go to one server; it gets processed through a sophisticated pipeline that includes encoding (converting to multiple resolutions for different devices), storage across distributed file systems, and delivery through a Content Delivery Network (CDN) that places copies of popular videos closer to users.
YouTube's architecture follows a microservices design, meaning different components—like video upload, processing, recommendations, comments, and analytics—run as separate services that communicate with each other. This approach allows for scalability and independent updates, but it also introduces complexity. The recommendation system alone, which caused the 2026 outage, is powered by advanced machine learning algorithms that analyze billions of data points about user behavior, video content, and engagement patterns to suggest what to watch next.
The 2026 Outage: What Actually Happened
The YouTube outage began around 8:00 p.m. Eastern Time on February 17, 2026. Within minutes, reports started flooding into Downdetector, a service that tracks website outages through user reports. The problem quickly escalated, peaking at over 320,000 reports in the U.S. alone. Users encountered various issues: some saw a completely blank homepage, others received the "Something went wrong" error message, while many found that video playback simply wouldn't start.
What made this outage particularly notable was its scope. Unlike previous YouTube disruptions that might affect only certain regions or features, this was a global event that impacted not just the main YouTube website and app, but also YouTube Music, YouTube Kids, and YouTube TV. This widespread impact suggested a problem with a core system shared across all YouTube services.
Google's engineering team quickly identified the root cause: "An issue with our recommendations system prevented videos from appearing across surfaces on YouTube," the company stated. The recommendations system—the complex AI that decides what videos appear on your homepage and in your suggested videos—had developed a critical bug that prevented it from serving any content at all. Since the homepage heavily relies on this system, the entire user interface essentially broke.
Common Causes of Service Outages in Large Platforms
YouTube's outage illustrates several common causes of service failures in large tech platforms. Software bugs, like the one that affected the recommendation system, are frequent culprits. In complex systems with millions of lines of code, even a small error can cascade through interconnected services. Configuration changes—when engineers update settings without realizing the downstream effects—can also trigger outages.
Hardware failures, while less common in cloud environments with redundancy, can still occur. Network issues between data centers or problems with external dependencies (like cloud service providers) can also bring down services. Additionally, cyber attacks, such as Distributed Denial of Service (DDoS) attacks that overwhelm servers with traffic, remain a constant threat.
How YouTube's Recommendation System Works—And Why It Failed
YouTube's recommendation system is one of the most sophisticated AI systems in existence. It processes over 80 billion pieces of information daily to suggest videos to users. The system considers your watch history, likes, dislikes, comments, what videos you've skipped, how long you watch, what time of day you're watching, and even what device you're using. This data gets fed into machine learning models that predict what you might want to watch next.
The system isn't centralized—it runs across thousands of servers working in parallel. When part of this distributed system fails, there are usually backups and failovers. However, in this case, the bug appeared to affect a fundamental component shared across the entire recommendation infrastructure. This could have been a problem with the model itself, the data pipeline feeding it, or the serving layer that delivers recommendations to users.
Interestingly, the outage revealed just how central the recommendation system has become to YouTube's user experience. Without it, the platform essentially loses its personalization—the very feature that keeps users engaged for hours. This dependency on a single complex system represents a potential vulnerability in YouTube's architecture.
How Tech Companies Prevent and Manage Outages
Large platforms like YouTube employ multiple strategies to prevent outages and minimize their impact when they do occur. Redundancy is key—critical systems have backups that can take over if the primary fails. Regular load testing simulates extreme traffic conditions to identify weaknesses before they cause real problems. Canary deployments allow engineers to roll out changes to a small percentage of users first, catching issues before they affect everyone.
When outages do happen, incident response teams follow established playbooks. Monitoring systems alert engineers within seconds of detecting problems. The teams work to identify the root cause, implement a fix, and verify the solution works before declaring the incident resolved. Communication is also crucial—keeping users informed about what's happening and when service will be restored helps manage frustration.
The Bottom Line: What We Can Learn from YouTube's Outage
YouTube's 2026 outage serves as a reminder of both the incredible complexity of modern digital services and their inherent fragility. Several key lessons emerge from this incident. First, even the most well-funded tech giants with thousands of engineers aren't immune to system failures. Second, as platforms become more interconnected and dependent on AI systems, single points of failure can have widespread consequences. Third, transparency about what went wrong and how it was fixed helps build user trust.
For everyday users, understanding how these services work provides context when they inevitably experience disruptions. For developers and engineers, the incident offers valuable lessons about system design, testing, and incident response. And for everyone, it's a reminder of just how much we rely on technology that, despite appearances of simplicity, represents some of the most complex engineering achievements of our time.
